test title
import unet
import importlib
importlib.reload(unet)
unet = unet.GenericUNet(input_channels=1, output_channels=64, init_zero=False, regis_scale=False)
unet.cuda()
image_A = sample_batch.cuda()
ufeatures = unet(image_A)class AttentionRegistration(icon_registration.RegistrationModule):
def __init__(self, net):
super().__init__()
self.net = net
dim = 64
self.blur_kernel = torch.nn.Conv2d(2, 2, 5, padding="same", bias=False, groups=2)
def featurize(self, values):
return self.net(values)
return self.net(torch.cat([
0* self.identity_map.expand(values.shape[0], -1, values.shape[2], values.shape[3]),
values], dim=1))
def forward(self, A, B):
ft_A = self.featurize(A)
ft_B = self.featurize(B)
ft_A = ft_A.reshape(-1, 64, self.identity_map.shape[-1] * self.identity_map.shape[-2])
ft_B = ft_B.reshape(-1, 64, self.identity_map.shape[-1] * self.identity_map.shape[-2])
attention = torch.nn.functional.softmax((ft_B.permute(0, 2, 1) @ ft_A), dim=2)
self.attention = attention
x = self.identity_map.reshape(-1, 2, ft_A.shape[2])
output = attention @ x.permute(0, 2, 1)
output = output.reshape(-1, 2, self.identity_map.shape[2], self.identity_map.shape[3]) - self.identity_map
#output = self.blur_kernel(output)
return output
ar = AttentionRegistration(unet)
ar.cuda()
inner_net = icon.FunctionFromVectorField(ar)
inner_net.assign_identity_map(sample_batch.shape)
inner_net.cuda()
0import tqdm
optimizer = torch.optim.Adam(unet.parameters(), lr=0.001)
epochs = 34
loss_history = []
for epoch in tqdm.tqdm(range(epochs)):
for A, B in zip(ds, ds):
image_A = A[0].to(icon_registration.config.device)
image_B = B[0].to(icon_registration.config.device)
optimizer.zero_grad()
teacher_phi = teacher_net.regis_net(image_A, image_B)(teacher_net.identity_map).detach()
student_phi = inner_net(image_A, image_B)(teacher_net.identity_map)
error = torch.mean((student_phi - teacher_phi)**2)
error.backward()
optimizer.step()
loss_history.append(error.detach().item())
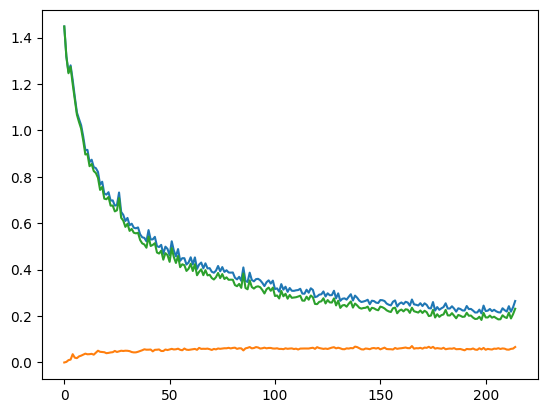
plt.plot(loss_history)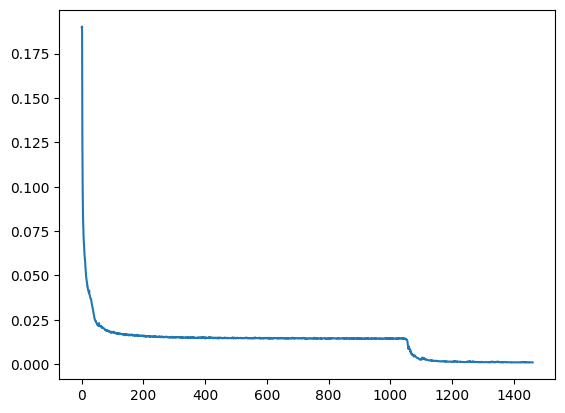
net = icon.GradientICON(inner_net, icon.LNCC(sigma=4), lmbda=.5)
net.assign_identity_map(sample_batch.shape)
net.cuda()def show(tensor):
plt.imshow(torchvision.utils.make_grid(tensor[:6], nrow=3)[0].cpu().detach())
plt.xticks([])
plt.yticks([])
image_A = next(iter(ds))[0].to(device)
image_B = next(iter(ds))[0].to(device)
net(image_A, image_B)
plt.subplot(2, 2, 1)
show(image_A)
plt.subplot(2, 2, 2)
show(image_B)
plt.subplot(2, 2, 3)
show(net.warped_image_A)
plt.contour(torchvision.utils.make_grid(net.phi_AB_vectorfield[:6], nrow=3)[0].cpu().detach())
plt.contour(torchvision.utils.make_grid(net.phi_AB_vectorfield[:6], nrow=3)[1].cpu().detach())
plt.subplot(2, 2, 4)
show(net.warped_image_A - image_B)
plt.tight_layout()
ufeatures = unet(image_A)
plt.imshow(ufeatures[0, 60].detach().cpu())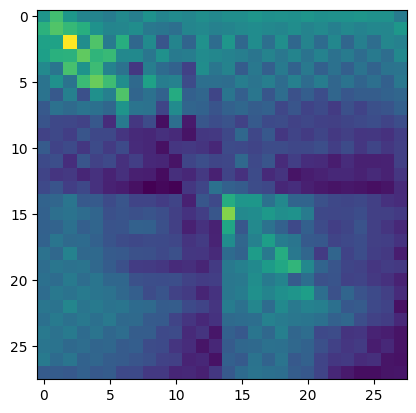
net.train()
net.to(device)
optim = torch.optim.Adam(net.parameters(), lr=0.0001)
curves = icon.train_datasets(net, optim, ds, ds, epochs=5)
plt.close()
plt.plot(np.array(curves)[:, :3])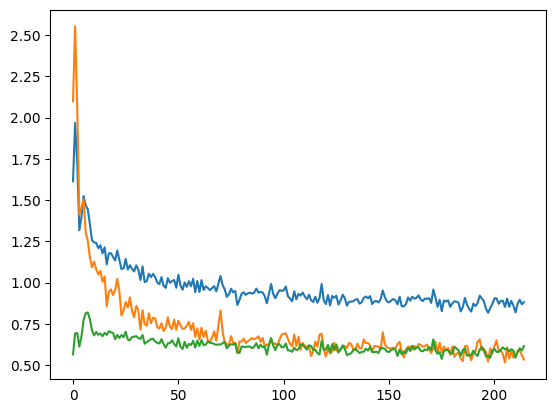
curves = icon.train_datasets(net, optim, ds, ds, epochs=50)
plt.close()
plt.plot(np.array(curves)[:, :3])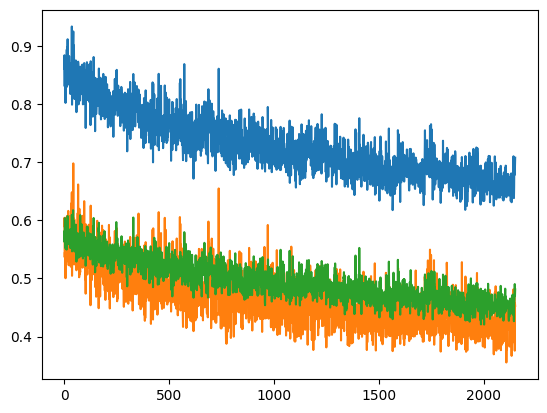
def show(tensor):
plt.imshow(torchvision.utils.make_grid(tensor[:6], nrow=3)[0].cpu().detach())
plt.xticks([])
plt.yticks([])
image_A = next(iter(ds))[0].to(device)
image_B = next(iter(ds))[0].to(device)
net(image_A, image_B)
plt.subplot(2, 2, 1)
show(image_A)
plt.subplot(2, 2, 2)
show(image_B)
plt.subplot(2, 2, 3)
show(net.warped_image_A)
plt.contour(torchvision.utils.make_grid(net.phi_AB_vectorfield[:6], nrow=3)[0].cpu().detach())
plt.contour(torchvision.utils.make_grid(net.phi_AB_vectorfield[:6], nrow=3)[1].cpu().detach())
plt.subplot(2, 2, 4)
show(net.warped_image_A - image_B)
plt.tight_layout()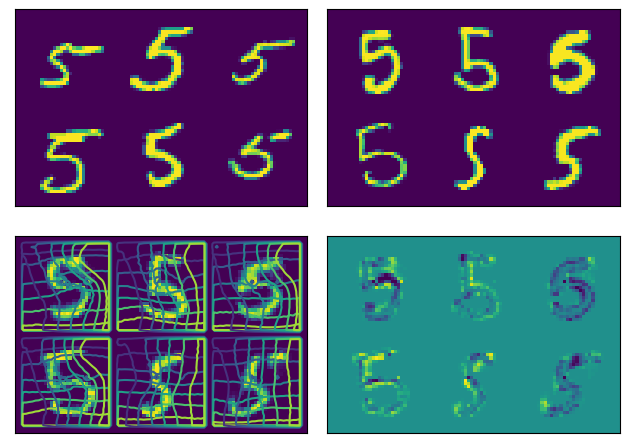
ufeatures = unet(image_A)
plt.imshow(ufeatures[0, 9].detach().cpu())
plt.colorbar()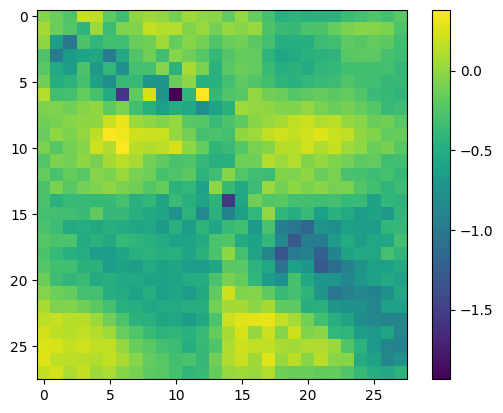 Back to Reports
Back to Reports subdavis.com forrestli.com
© Hastings Greer. Last modified: April 11, 2025. Website built with Franklin.jl and the Julia programming language.